It's not often I need to make icons but it happens sometimes. Having no favorite tool for creation I tried GIMP. I was surprised how easy it can create icon with several images.
First of all create image with biggest size you need. I chose 64x64. You might also want to create a layer with background to see the result better. I usually use white or dark-blue depending on foreground image lightness.
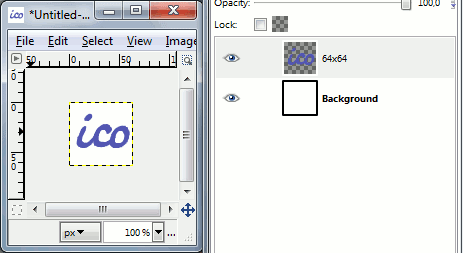
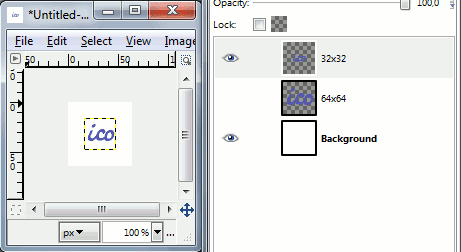
Then duplicate the layer with icon and select "Scale Layer.." from layer's right-click menu. Resize it to next size you need, ex. 32x32. Note, that unlike in Photoshop you can have layers with different size. By default you'll see current layer's border.
Let's create the last layer 16x16 and colorize layers with different colors. Also delete background before saving icon (leave only layers with icon images).
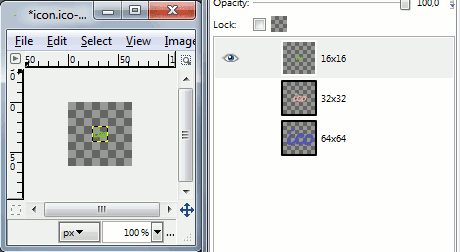
Now save document as .ico file.
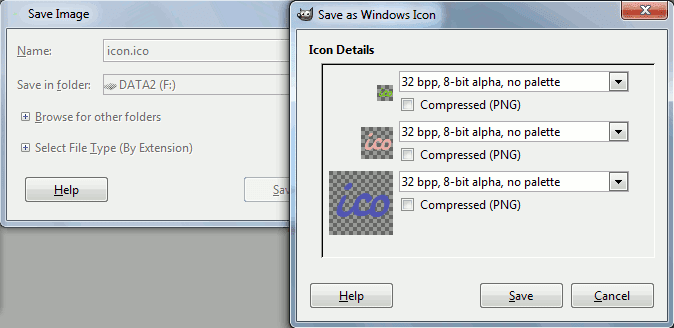
Now you have icon with all the images. On the following screenshot explorer shows different images in file list window (16x16 icon) and preview window (smaller sized 64x64 icon).